

Timing is all you need: Musings on LLM Tooling's Next Chapter
What do LLM Toolings have (not) in common with the Modern Data Stack?

I want to start by saying that this piece mainly comes from a venture perspective - there are many beautiful and great ways to build an impactful company, one part of which is the very biased venture world. Biased towards outsized outcomes, power law curves, and category winners, so please take all the things below with some grain of salt.
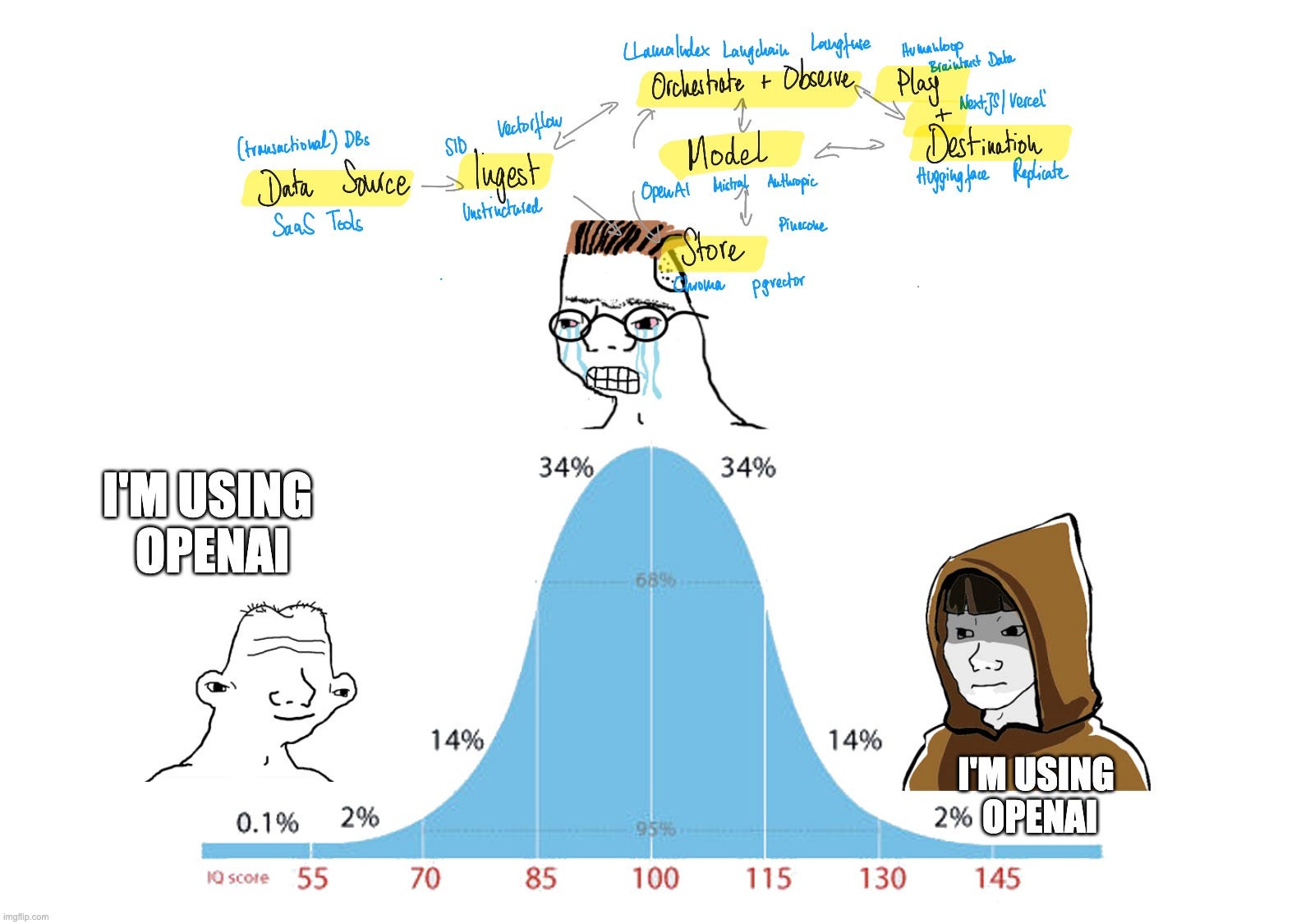
I think LLM Tooling today is where BI software was in the 2010s…
…but it won’t take ten years to get to what BI/data has become today. What do I mean by this analogy?
When GitHub Copilot, Stable Diffusion, Midjourney, and ChatGPT emerged in 2022, leading to large-scale adoption among end-users, companies were immediately exploring how to adopt GenAI into their businesses in the hopes of unlocking the next level of productivity and capability over the last year. We’ve pretty much seen three ways how companies adopted GenAI:
(1) companies were looking to increase the productivity of their workforce with internal applications like search, knowledge, and writing assistants
(2) non-AI software companies like Notion quickly added text and image generation as a feature on top of their products
(3) entirely new AI-native companies that could not exist before, like Runway ML, emerged, and some even majorly contributed to the birth of the GenAI space

With the new gold rush, a new type of company set out to build the picks and shovels to help others adopt and leverage LLMs. In addition, many existing companies that were somewhat niche before suddenly gained widespread relevance, such as the entire vector database space. Investors, in turn, quickly jumped on that opportunity, created market maps, launched thought pieces and startup ideas, learned new vocabulary like RAG. As a result, an entirely new investable category emerged: the LLM tooling space.
Because we love to think in frameworks and mental models, many analogies between the LLM Tooling space and the modern data stack space (MDS) were employed, which, in turn, was probably one of the hottest infra categories right before the emergence of LLMs. Equipped with the hope of building many similar-sized (paper) outcomes that MDS has produced previously, hundreds of new startups embarked on a mission to ride the LLM wave, with investors pouring billions of dollars into the tooling and model layer.
While I generally like the analogy with the modern data stack, I think we’re one step too early and might have come to those conclusions too quickly: I believe that LLM Tooling today is where BI was in the 2010s and NOT necessarily in the MDS era of the last five years: Companies in that space will win by solving use cases through delivering user benefits end-to-end, not by improving those use-cases (yet). Let me explain.
The analogy between Modern Data Stack and LLM Tooling
So, what is the Modern Data Stack, and what are the analogies the industry applied to the LLM tooling space?
In the years leading up to the 2020s, when the amount of data has been exploding, making sense of it and managing the complexity has become crucial for modern companies. The overall premise was that data and insights lead to better decisions and outcomes for companies and users. The ideal state of being data-driven or data-informed at your core pressured companies into the rise of dedicated data teams and the adoption of sophisticated data tools. While data tools have existed for decades, the volume and requirements of data and competitive pressure asked for a more sophisticated solution space, and existing BI solutions like Sisense or Looker were not up for the new challenges. That led to one of the hottest categories in the last five years, with the modern data stack producing multiple venture-scale opportunities and unicorns.
The “modern” part essentially means that the entire data journey from raw data to insights/reports/actions was broken up into multiple sub-steps in which best-in-breed companies were born and scaled to success. (For simplification, I will only focus on the classic batch analytics use case for now) as the answer to holistic one-tool-rules-them-all approaches of the past. Let’s break it down:

Data Source: This is where siloed raw data is generated and initially stored, such as (transactional/production) databases (e.g., Neon) or SaaS tools and other services (e.g., Stripe, Hubspot, etc.).
Ingest: In this step, data from the data sources get fetched, connected, and piped into the next step (typically into the „Store“ step). Traditionally, data is transformed here, aka put into a more usable representation (ETL era), now increasingly just being fetched and dumped into the „store step“ in a data warehouse or lake (ELT era) directly. Venture-scale businesses are Fivetran or Airbyte, for example.
Store: Data is pulled and dumped into a so-called data warehouse or data lake where data resides until being used and further processed. These databases can be optimized for analytical large-scale workloads and split across multiple relational “tables.” The big players here are Snowflake and Google’s BigQuery.
Transform: Data in, e.g., “tables” in a data warehouse are combined with other tables and shaped into a useful representation (e.g., “aggregate all our revenues from the last five years in South America”). The most well-known company here is dbt.
Play + Destination: This is a very broad space that includes data visualization tools, developer environments and interfaces, and data apps - essentially the primary interface between data/insights, end-user, and subsequent action. Venture-scale companies are Deepnote, Hex, Graphy, Metabase, Streamlit, or Retool.
Orchestrate + Observe: The meta-level of the data pipeline - tools in this category are responsible for triggering (parallel) data flows to get a fresh batch of data and insights, for example, checking the quality of the data or observing and managing experiments and triggering alerts when something is wrong, and even prevent things from going wrong in the first place. Tools include Airflow, Y42, Dagster, Monte Carlo, Prefect, and Synq.
Regardless of whether those valuations are still justified in hindsight, the modern data stack has de facto changed the data industry and produced (paper) unicorns and soonicorns in each of those buckets, with Snowflake, Fivetran, dbt, and Monte Carlo leading the pack.
Now, let’s turn to today's LLM Tooling stack, and we will see where the analogies come from.
Toolings to put LLMs in use
Similarly to how the data explosion triggered the birth of the modern data stack, technical advances and broad availabilities of LLMs triggered the rise of LLM toolings to make these new capabilities accessible and useful in UIs, workflows, and background jobs. The guiding hope for every participant in that tooling universe: If LLMs become at least as ubiquitous as the use of data today, the LLM Tooling Stack will produce as many outsized opportunities similar to the modern data stack.
If we map out the LLM Tooling pipeline, we’ll see that the steps are astonishingly similar to the modern data stack and even share some of the same tooling providers (e.g., Airbyte for ingesting data). Let’s roughly break down the LLM tooling into sub-steps, too (for simplification, I omitted some steps like caching or guard railing tools).
Data source: Raw data originates here and is scattered across internal databases, SaaS tools, and other services. Specifically, this data here is not necessarily the data on which the LLM is trained, but typically used to augment the results of the LLM (hence also the term retrieval augmented generation / RAG) to be able to tap on data the LLM has not seen and access to during pre-training.
Ingest: Raw data is collected from different sources and file formats (raw text, PDFs, HTML, etc.) and piped into the subsequent steps. Here, raw data is typically pre-processed (e.g., cleaned and then chunked) and then converted via so-called embeddings (simply said, this turns raw data into a contextualized “LLM-readable/retrievable” format). Companies here are unstructured.io, sid.ai, Vectorflow, Superlinked, and Airbyte, an established MDS player.
Store: Vector databases take on the job of storing, contextualizing, and quickly finding vectorized data to help augment the results of the LLMs. Many companies emerged before the LLM era to solve tasks like search. Companies here are Pinecone, Chroma, and also conventional database providers that add these capabilities on top of their offerings like MongoDB, elastic, or Neon and Supabase via pgvector.
Model: This is the core and raison d’être for the LLM tooling stack and a universe in itself with its own set of toolings (e.g., ML frameworks, experimentation suites, workload managers, tuning/RHLF tools, deployment platforms, etc.). These “smart next-word predictors” can solve many tasks incredibly well and cost a ton to train. Companies here are OpenAI, Mistral, or Anthropic.
Play+Destination: Most teams today either embed the LLM capabilities into their text field, provide chat-based UIs, or deploy them via API. Vercel has positioned itself as the frontend layer for modern AI-based web apps. Same for companies like Huggingface/Gradio, Modal, or Replicate for API-based or “headless” deployments.
Orchestrate+Observe: This step overlooks and stitches all pieces of the LLM tooling stack together. Prompts are typically managed here as well and put into relation to the model/RAG output with an evaluation step turning everything into an improving cycle. Companies here are Langchain, Llamaindex, Braintrust Data, or Langfuse.
So, if we overlay the MDS and the LLM tooling stack, we could probably see where these analogies come from, somewhat justifying the interest and attention this new tooling stack receives today spurred by LLMs. However, after accompanying many great founders in that space, speaking to many (prospective) users in recent months, looking at a couple of stats, and tinkering around myself, I have come to the realization that we might be off timing-wise to see MDS-like outcomes soon.
This is pretty much based on two main observations:
(1) The adoption and retention of LLM capabilities lag behind expectations
(2) OpenAI’s models, coupled with Microsoft’s distribution power, are dominating
Adoption and Retention lag behind expectations
Let’s be clear: Unlike other recent potential technological platform shifts like crypto, productivity gains by GenAI are undeniable, especially amongst developers, creatives, and text-heavy workers. For example, developers are 55% more productive with GitHub copilot with ~40% of the code they’re checking being AI-generated, and I hear developers threatening to leave or are ready to pay exorbitant amounts of money if Copilot was taken away from their workflow. Adobe states that Firefly has been used to generate over three billion images since launch and has seen a 10x adoption compared to the last releases.
While we’re all clear on the promises that GenAI holds, looking at statistics and anecdotes gives us a more sobering truth: Somehow, the adoption (and also retention) of the use of LLM capabilities lags behind expectations. For example, most enterprises plan to adopt some LLM capability, but only 10% have so far, mainly consisting of (US) tech-savvy companies that run models at scale and in production internally and externally as part of their product offerings.
Anecdotally, when we look more downmarket in early-stage startups, we see a similar picture, with the majority of adopters coming from small tech bubble like the Notions or Raycasts of this world.
The internal usage of LLM-powered assistants like ChatGPT gives us a more hopeful picture with a 49% adoption rate, but the growth rate has seemed to slow down, and user engagement and retention numbers are somewhat trailing, which, by the way, applies to the general consumer landscape in GenAI.
Admittedly, this is simply the nature of new technology, and like always, penetration curves will eventually pick up over time. Still, the reasons why LLM adoption lags behind expectations are real and broadly fall in one of the following buckets:
Companies and teams can’t implement and maintain LLMs: On the one hand, I see most companies and teams being genuinely interested in LLMs and convinced by this new technology's promises. The topic GenAI and its impact on business have probably appeared in all board meeting agendas of software companies in 2023.
However, LLMs have not been adopted in those companies yet because many do not have any idea or good intuition about where and how to implement the models or have no meaningful use cases. This goes for internal use cases but even more for external end-customer-facing capabilities.
Even worse, if they had those ideas, some would not have the expertise to implement them primarily due to the lack of talent in-house (think more traditional companies that struggle to attract developers, let alone AI engineers).
Another reason for their hesitance is the lack of confidence to navigate the world and behavior of LLMs. Due to their stochastic nature, uncertainty around data security, and a lack of education and feel for LLMs, many companies are simply too scared to embark on the LLM journey for now, deciding to sit out until they feel pressured by some of their peers’ courage.
Lastly, even if companies have appropriate use cases that can be solved by LLMs and the resources available to prototype, they struggle to productionize, maintain, and scale those abilities on their own.
Companies can implement LLMs but decide not to: Others have the ability to embark on their LLM journey but choose not to. Especially early-stage companies who fight for their lives to find product-market fit or turn into hyperscale mode typically have other more important issues to deal with than incorporating LLMs if LLM is not core to their business. As a result, GenAI does not make it beyond a Notion strategy one-pager. While it’s enticing for many tooling companies to target the early stage bracket due to shorter feedback cycles, these types of customers might pivot or not even be around after a few months, let alone having a concrete need for LLMs right now.
Enterprises simply take longer to adopt things: Let me simply quote Elad Gil here: “[ChatGPT’s] launch was only 8-9 months ago, and GPT-4 did not come out until five months ago. Given that large enterprise planning cycles often take 3-6 months, and then prototyping and building will take a year for a large company, we are still very far away from peak AI usage or peak AI hype. Most large enterprises are still trying to analytically sort what “AI” means for them, and are still many quarters from embracing this new technology.”
LLMs are not helpful and accurate enough yet: If you have been chatting with ChatGPT or calling models via API, you might have felt it yourself: LLMs often talk nonsense but deliver it with very high confidence - they hallucinate. According to Retool’s great “State of AI” report, most practitioners even find AI overrated, with model output accuracy and hallucinations as their top 3 pain points in developing AI applications, which leads to broader hesitance.
One of the OGs in AI, Yann LeCun, even goes as far as saying that LLMs are not that smart as they lack common sense, a model of the world, reasoning, persistent memory, and hierarchical planning.
RAG and finetuning can help here, but how many internal teams can maintain a barebone RAG stack at scale, let alone continuously fine-tune the models?
As a result, many companies remain in passive observer mode as they cannot afford to deploy LLMs with a non-zero probability of talking nonsense, let alone chaining them in multi-step agentic workflows, as mistakes here accumulate and diverge exponentially.
LLMs + applications suffer from the “new shiny toy problem”: Especially in the consumer/prosumer space, we can observe an interesting phenomenon: The adoption of GenAI and GenAI-powered applications sets records, but engagement and retention trail behind their non-AI counterparts.
I believe one of the drivers is the “new shiny problem” - interacting with an eloquent and creative artificial intelligence is fun, but over time, it is hard to change human behavior immediately, and most of them simply fall back to whatever they did before. Also, there are only so many AI avatars you want to generate of yourself before you get bored.
The adoption of LLMs is a leading indicator for the tooling space, with models and capabilities defining what should be built and used downstream in the tooling space. Simply said, if you barely use LLMs, why would you use any toolings? The Retool report gives us additional proxies: 48% of LLM practitioners do any customizations (which would raise the need for additional toolings), and not even 20% of LLM users use a vector database to support LLM’s outputs. This is a good segway to my second main observation last year.
OpenAI is still OP
If you survey your friends, you will see most of them still mostly use OpenAI’s models, despite the Mistrals, Anthropics, and the Googles of this world closing the gap rapidly. Retool reports that “various flavors of ChatGPT (4, 3.5, and 3, in that order) are the most frequently used models for most respondents (80.1%)”, and Langchain states that OpenAI and AzureOpenAI (which is basically Microsoft hosting an OpenAI model) are the top two models developers in their ecosystem use. I attribute their dominance to a mix of the following guesses:
OpenAI was the first mover at training and deploying a helpful model (GPT-3 & 3.5) and used it to build their distribution.
They are (I say generally!) very developer-friendly by investing a lot in good user experience with different capable products, interfaces, ecosystems, and availabilities.
Their models are still the best available in the market - look here and here. Other models are catching up, with Mistral being the hottest candidate to release a GPT-4 level this year. However, OpenAI is probably putting the finishing touches on GPT-5 while we’re reading this piece.
With OpenAI’s dominance, there are two main implications for the tooling space.
In a somewhat monopolistic setup, OpenAI can reach escape velocity simply by leveraging economies of scale and an integrative approach. Through their distribution turbocharged by Microsoft, they can continue to lock in the users by providing the best models with the best availability and price. Locking in users means they can continue RLHF’ing at scale and might be able to tap into new or hard-to-access data to continue producing the best models that, in turn, further lock in the users. Integrative not only means going upstream in the stack but also moving downstream into the tooling layer - simply put - if you are using models mainly from one provider anyway, why not also use the tooling built by said provider and optimized for those models? Despite OpenAI playing the friendly platform and ecosystem guy, they have shown to fiercely expand across their value chain by going more agentic, bundling in data ingestion, and broader RAG functionalities. The low-hanging fruit capabilities that tooling startups want to capture will be eaten up by anything on OpenAI’s product roadmap or handed off to Microsoft for the last-mile logistics.
As the fast-moving pioneer in all things GenAI, I expect OpenAI to get to a ChatGPT moment for all different modalities beyond text (if they haven’t already done so with Dall-E, Whisper, Speech Synthesis, etc.). With GPT-4V, we can already see tremendous value being unlocked when only two modalities are used in conjunction (in this case, it’s image and text). When model capabilities change, tooling companies must adapt quickly to accommodate more modalities. This is incredibly challenging for the young and resource-light tooling companies as they typically start with supporting one modality. Before they fully cracked that market, OpenAI has already shipped multi-modal support, making those tooling players almost obsolete.
Here is an interesting graph that supports these observations. It shows the ratio of Langchain downloads, which I consider as today’s proxy for the LLM tooling market, to OpenAI’s downloads decreasing from 60% to the 35% area.
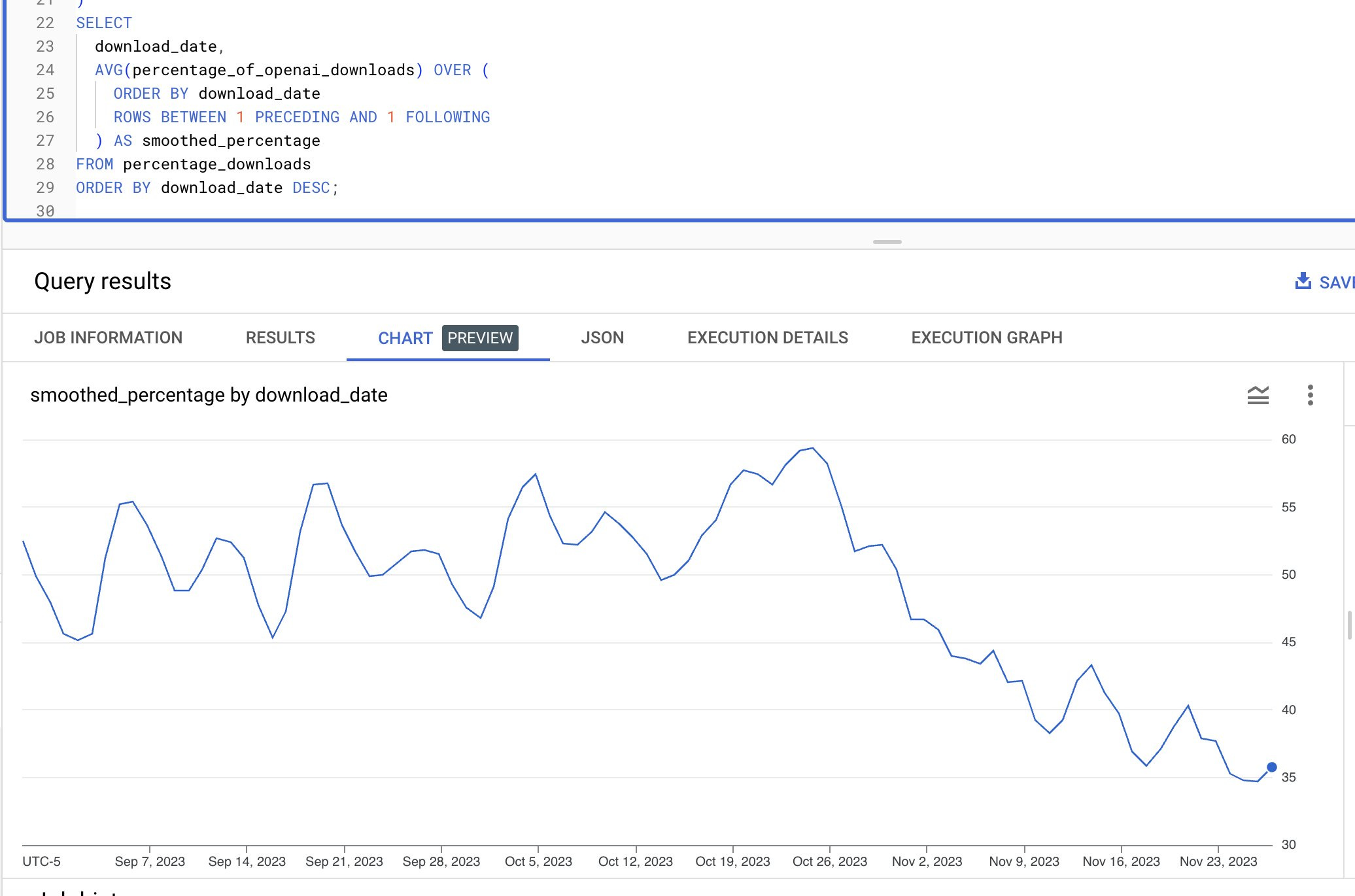
Zooming out, developer tooling, in general, is interesting and probably more nuanced with the developer persona and their needs more heterogeneous than we’d like to admit - outside of holistic products suites in the data and cybersecurity space, have you ever wondered why outcomes were not larger than Gitlab’s 15B IPO and GitHub’s 7B acquisition even though there are ~30M developers that can be addressed (with a developer to designer ratio of around 10:1)?
The next chapter of LLM Tooling companies
Because of those two observations (adoption lower than expected and OpenAI dominating), I believe tooling companies, sooner than later, will be focusing more on solving use cases, delivering their value out-of-the-box, and going more end-to-end. In addition, I believe a white glove handholding and consulting-like approach to help early adopters navigate the new and uncertain terrain is the initial winning move. This can be addressed best by consulting firms themselves or large software companies with massive distribution like Microsoft, who can compensate their services with higher ACVs.
As a result, if I had to make a guess, I believe LLM tooling will consolidate around these not mutually exclusive use cases:
“Give me AI out of the box. I don‘t want to deal with anything else. “ —> One tool that rules them all; will exist both horizontally, like ChatGPT, Langdock, or Perplexity, and verticalized, like Harvey

“I want my data to be very accessible by me or AI” —> Ingest + Store

“Give me a command center to see, understand, control, and improve the process and the output” —> Orchestration + Observe + Play

While most young startups can only start with a beachhead strategy given their limited resources, they need to expand quickly and ideally follow the compound startup strategy and deliver out-of-the-box capabilities. Hence, a longer breath is needed to play the long game for these new startups to be able to make multiple bets over time: community buy-in and adoption, ecosystem partnerships & deep integrations, and a more consultive sales motion to accelerate broad distribution, next to trying to expand the product offering. In all cases, these milestones will be less obvious initially, so raising a financing round that gives those companies some more buffer at the early stages to make them able to play the long game would make sense. This is even more relevant for tooling companies that follow a bottom-up open-source strategy in which relevant commercial milestones are usually delayed by +2 years.
At the bottom line, I think the LLM tooling space needs a Sisense/Looker moment before we can have a dbt.
Some silver linings
While digesting these observations is a bit sobering, I don‘t believe it will take too long until the GenAI space provides a fruitful soil for many tooling companies to flourish and drive impact, even with a best-in-breed strategy. Some reports claim the adoption rate of AI is 2x that of other technological shifts. That means we don‘t necessarily have to wait ten years to see a dbt-like outcome in LLM tooling because:
Unlike BI/data, LLMs will have much stronger exposure in external-facing use cases, opening both a larger market and demanding different requirements due to higher scrutiny.
Enterprises will open up the floodgates soon, primarily once models can address their homogenous needs (e.g., through open source; see below) and meet their bar of helpfulness and accuracy.
The commoditization through open source is inevitable and will make models much more accessible for all needs. While I still believe that OpenAI will maintain its lead across many modalities, there is a “threshold of acceptance,” which means that at some point, all models will be in the area of “good enough,” with newer models decreasing in marginal utility within one modality. For example, open-source allows for on-prem/cloud-prem deployments, which many companies prefer instead of sending data to proprietary third-party providers / OpenAI. Of course, the big question is whether this dynamic again is only a temporary arbitrage similar to the cloud era.
Ironically, due to OpenAI’s dominance, big tech companies have become less open with their research (Google put in the work and famously fumbled it). This is interesting as there will be a time beyond today's attention/transformer-centric approach. Research labs, including the ones of Meta and Google, have shifted their attention to full-force AI, entering a Cold War-type situation, pushing the frontier of what could be beyond GPT-4V, leading to a commoditization of the model space. Commoditization also means there will be a broader (model) provider universe that needs to be dealt with and, then again, a new opportunity for third-party tooling providers to manage that complexity and flourish.
And who knows, maybe an analogy between MDS and LLM Toolings can be valid after all. It is to be seen if the modern data stack will be able to cover extensive enough use cases (next to people getting overwhelmed by managing multiple tools simultaneously) to justify that many outsized outcomes, and we might eventually see some consolidation around Databricks and Snowflake soaking up the entire analytics fabric.
Make sure to check out my other posts on
Thanks to John Luttig, Leigh Marie Braswell, Marc Klingen, Dan Meier, Saket Kumar, and Finn Murphy for letting me pick your brain and recycle some of your original ideas.
Disclaimer
Views expressed in “posts” (including podcasts, videos, newsletters, and social media) are those of the individual GC personnel who wrote the post or is quoted therein and are not the views of General Catalyst Group Management, LLC, “GC”) or its respective affiliates. GC is an investment adviser registered with the Securities and Exchange Commission. Registration as an investment adviser does not imply any special skill or training. The posts are not directed to any investors or potential investors, and do not constitute an offer to sell — or a solicitation of an offer to buy — any securities, cryptocurrencies, or any financial instrument or property, and may not be used or relied upon in evaluating the merits of any investment. Additional important information about GC, including Form ADV Part 2A Brochure, is available at the SEC’s website:
http://www.adviserinfo.sec.gov
Nothing here should be construed as or relied upon in any manner as investment, legal, tax, or other advice. Any projections, estimates, forecasts, targets, prospects, or opinions expressed in these materials are subject to change without notice and may differ or be contrary to opinions expressed by others. Any charts or figures provided here are for informational purposes only, and should not be relied upon when making any investment decision. Certain information contained in the content has been obtained from third-party sources. While taken from sources believed to be reliable, no one has independently verified such information and there are no representations about the enduring accuracy of the information or its appropriateness for a given situation.
To the extent any content authored or provided by any GC personnel in this forum or medium makes reference to any company in which any of the funds or vehicles advised by GC have an economic or financial interest, previous or current, none of the information provided or opinions expressed herein are connected in any way with GC’s business activities, and GC did not provide any information or assistance in the creation of this content.
Excellent piece.
> Still, the reasons why LLM adoption lags behind expectations are real ...
Do you think enterprise-ready (or on-prem) RAG will solve most of these?